Forecasting bitcoin value with ARIMA
This was my final project for PSTAT 174, Time Series, Fall 2017. It has been changed slightly from the time it was completed to this version you see here.
Abstract
This analysis attempts to build an accurate forecasting model for the opening price of the bitcoin cryptocurrency, using data from an entire year and the Box-Jenkins methodology. This process consisted of model identification (after Box-Cox transformation and differencing), model selection by comparing AICc, parameter estimation using maximum likelihood estimation, and finally model diagnostics from looking at the ACF and PACF of the residuals.
As it turns out, the two models with the lowest AICc, ARIMA(2,1,1) and ARIMA(1,1,2), were similarly flawed on account of the inherent heteroskedasticity in the original data, which was discovered when running model diagnostics.
Ultimately it was decided that the ARIMA model was unfeasible for modeling this particular dataset. Having said that, both models resulted in very similar results and confidence intervals that contain the true values, with the ARIMA(2,1,1) model \(X_t - 0.0546X_{t-1} = Z_t + 0.0167Z_{t-1} + 0.0536Z_{t-2}\) proving only slightly more effective when forecasting only 10 values into the future. It is suggested perhaps that the GARCH model which more effectively deals with heteroskedastic data would be better for forecasting this data.
Introduction
This dataset is the opening price of the cryptocurrency bitcoin for 366 days, I chose a random year (October 9 2015 - October 8 2016). Cryptocurrency is a digital currency, with bitcoin being the most well-known. It is untraceable and is known for its usage for purchasing illicit goods and services. With internet anonymity and privacy becoming more important in the modern day, the value of untraceable currency has skyrocketed in the past several years. I want to be able to forecast the value of bitcoin in the future, based off of its value in the past. The dataset was found on Kaggle.com, which in turn got the data from coinmarketcap.com.
Body
Preliminary Plots
To first analyze the dataset, I want to read in the data and then plot its time series. The data is organized to where the values are the top are the most recent, and those at the bottom are the oldest, so I will have to reverse this. I’m going to subset the data to a certain range in the middle so that I can compare my forecasting with actual existing data. After doing this, I will plot the series along a trend line or ‘line of best fit’.
set.seed(100)
df <- read.csv(here::here("data", "bitcoin_price.csv")) %>% select(c(Date, Open))
df$Date <- as.Date(df$Date, "%b %d, %Y")
df <- df[order(df$Date), ]
# taking a 356 observation subset of the data
df_sub <- df %>% subset(Date >= "2015-10-09" & Date <= "2016-10-08")
# plotting with a LOESS line
par(mfrow = c(1, 1))
ggplot(df_sub, aes(x = Date, y = Open, group = 1)) +
geom_line() +
xlab("Date") +
ylab("USD") +
ggtitle("Opening Price of Bitcoin") +
geom_smooth(method = "loess", level = 0)## `geom_smooth()` using formula = 'y ~ x'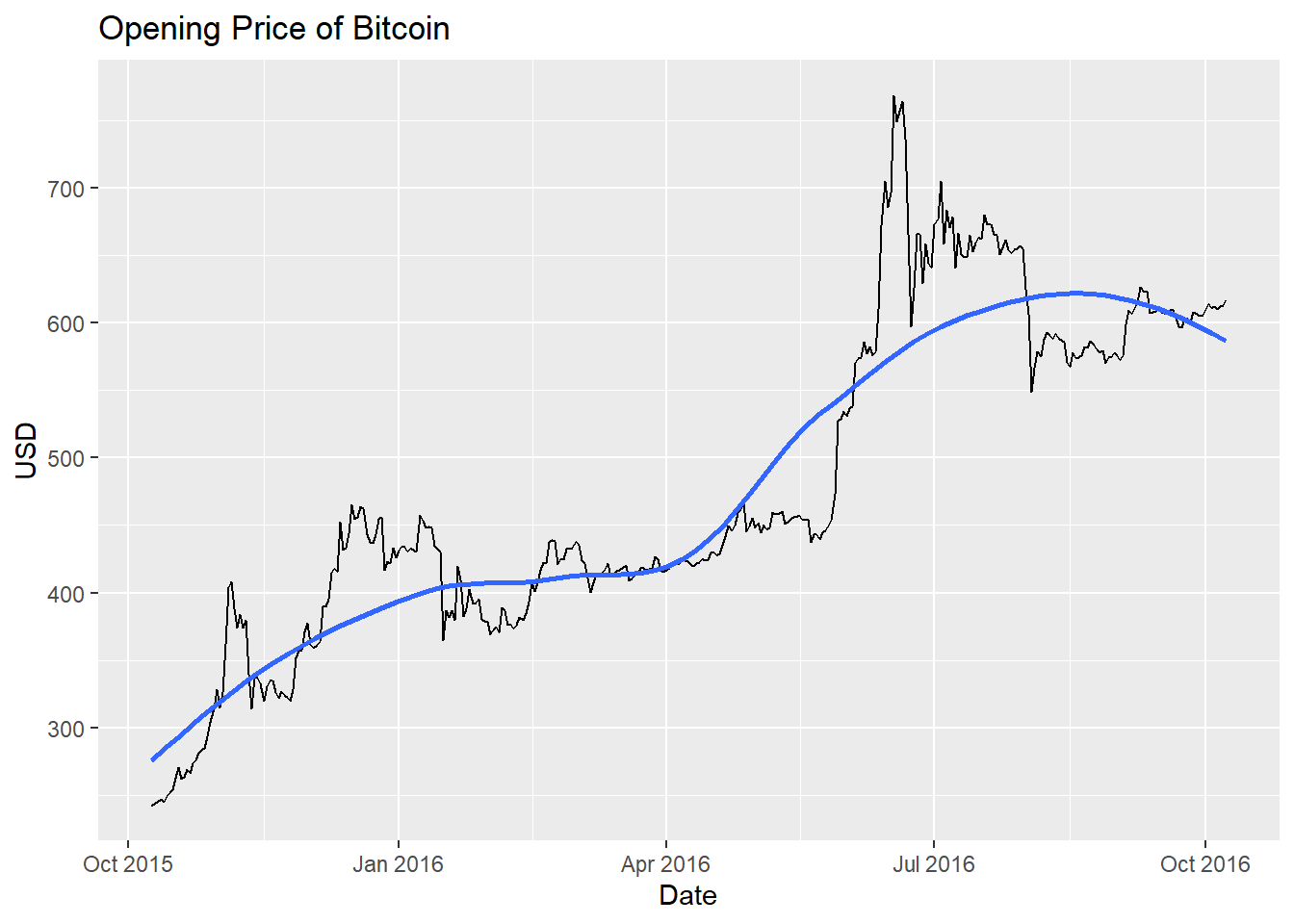
Trend, Seasonality and Sharp Changes
There is a very clear upward trend in the data, several sharp changes, and the mean is in no way constant over time. All of these are red flags that the data is not stationary. I do not believe from looking at the data that seasonality is an issue since there is no consistent change that occurs periodically. The issue of the trend can and will be addressed via differencing, and similarly seasonality can be addressed in this way but we need not do that here. The sharp changes do make a difference in terms of the variance, which we will attempt to make constant via power transformations such as through the Box-Cox transformation.
Transforming
With the end goal of forecasting, the first step after looking at the data is to transform it to make it stationary, i.e. make it so the future behaves as the past. In order to determine the best way to do that, we should look at the ACF (auto-covariance) and PACF (partial auto-covariance) plots, which depict how data are affected by the observations that precede them. This will also give us an idea of the model for the data.
The autocorrelation of data, represented by the function \(\gamma_X\) for some data \(X\), is the correlation in the data between two different points in time. One of the conditions for stationarity of a dataset is for the autocorrelation between two points in time \(t_1\) and \(t_2\) to be equal to the autocorrelation of the difference between \(t_1\) and \(t_2\). The partial autocorrelation is the original ACF, controlling for the values of the time series at all shorter lags. Properties of these plots help us determine the order of the AR and MA components of our ARMA model.
AR (auto-regressive) models depend on their past values, an error term, and sometimes a constant. MA (moving average) models depend linearly on the current and past values of white noise error terms (which is random). The combination of them, together with differencing, consitute the ARIMA model.
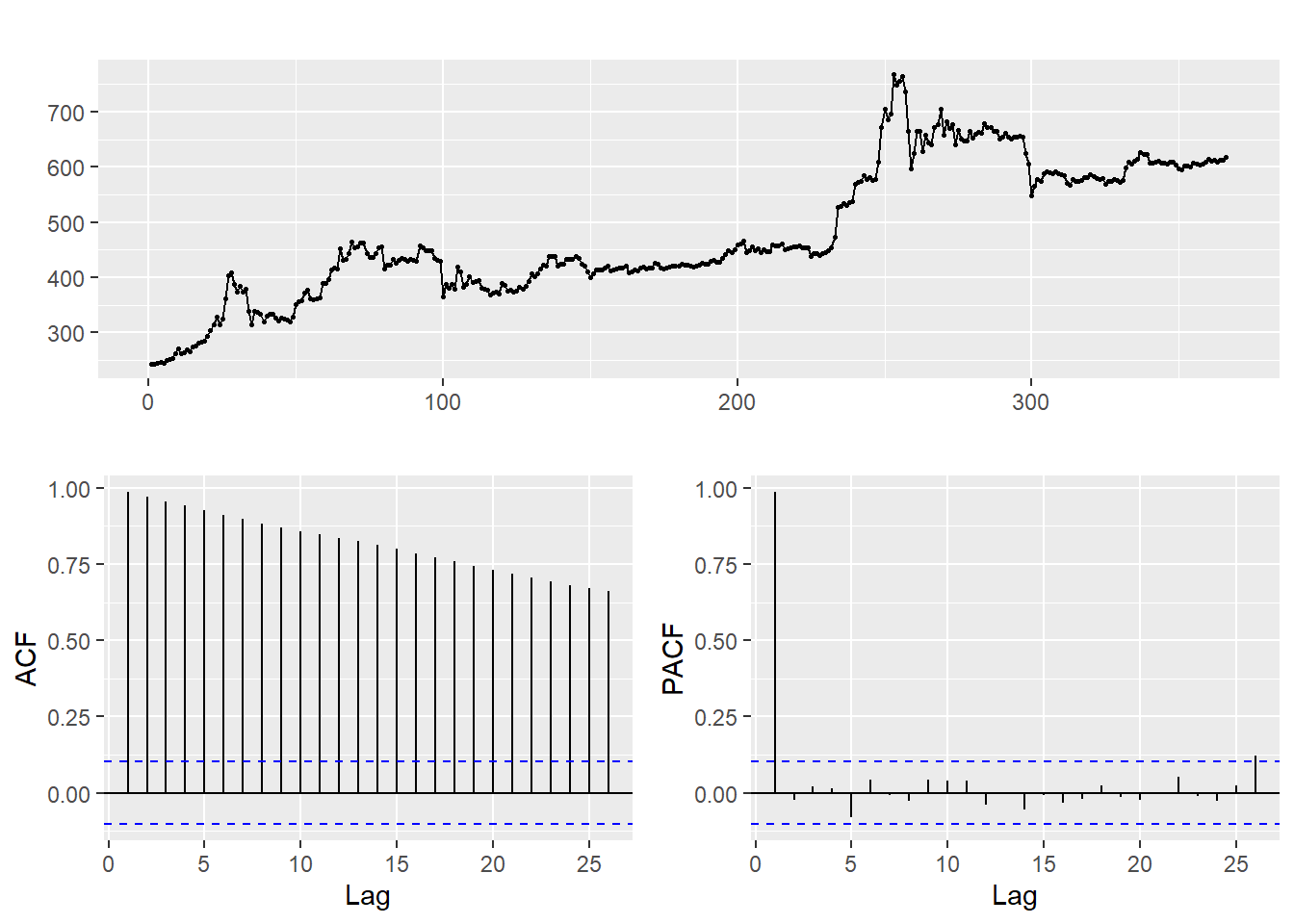
The ACF of the data decays gradually, whereas the PACF cuts off abruptly. The gradual decay of the ACF tells us that we should difference the data, which would also address the issue of the upward trend.
Box-Cox Transformation
We would like to begin by using the Box-Cox power transformation, which is a method that helps to Normalize data. This method finds a value \(\lambda\) which maximizes the log-likelihood and then the data is raised to the power of \(\lambda\). The higher the likelihood, the better (more likely) the model parameter. Power transformations such as the Box-Cox help to stabilize the variance which is imperative for Box-Jenkins modeling.
par(mfrow = c(1, 1))
# library(MASS) is loaded
bcTransform <- boxcox(open ~ as.numeric(1:length(open)))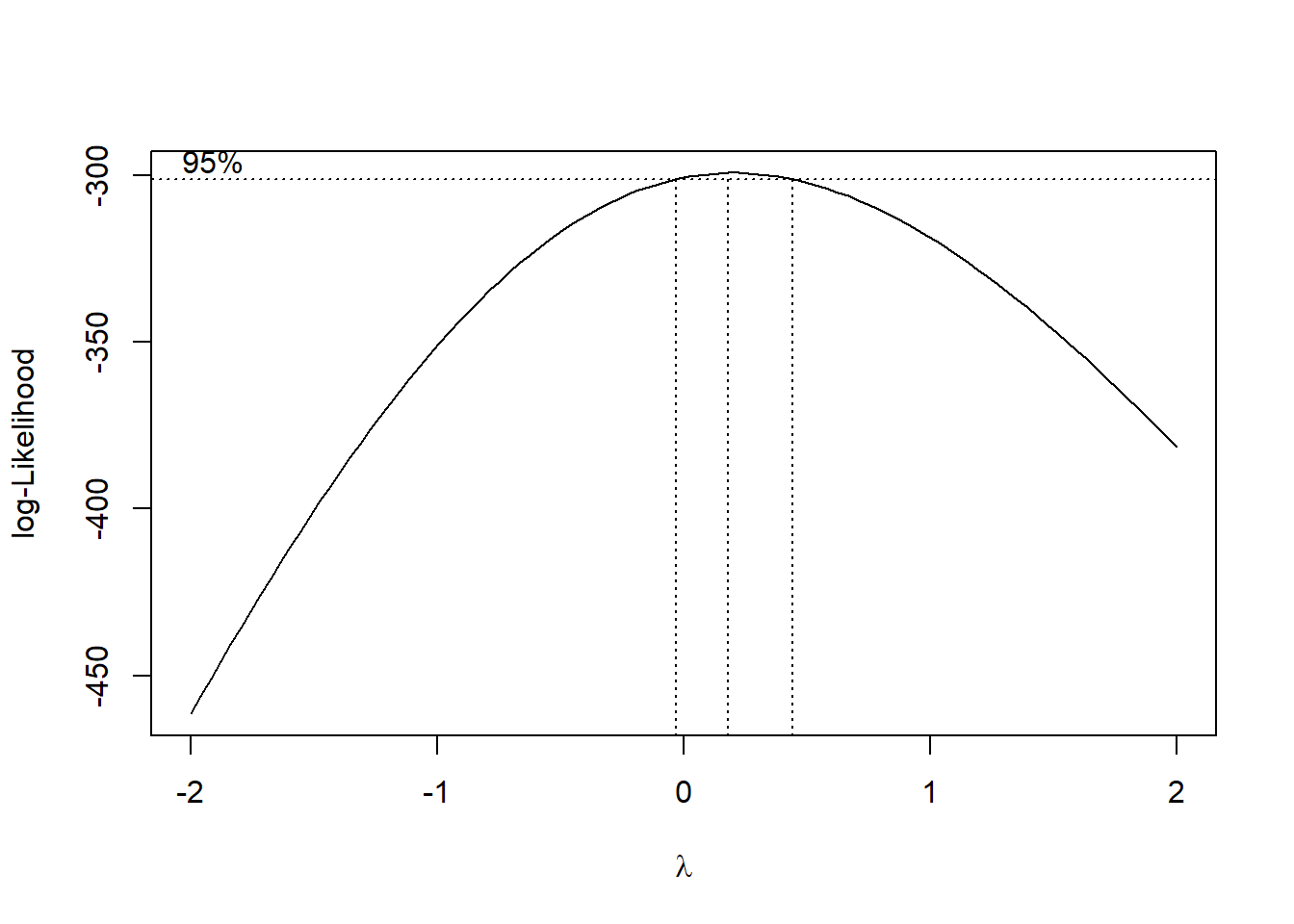
# value of lambda which maxes log-likelihood
best.lambda <- bcTransform$x[which(bcTransform$y == max(bcTransform$y))]
best.lambda## [1] 0.1818182We see that the ideal value for \(\lambda\) that maximizes the likelihood is \(0.181\), but the log function, \(\lambda = 0\), is within the confidence interval so we can use this instead. Here we will apply the transformation, then compare the variances of our original data with the transformed data.
# transforming the data
df_sub$Open_tr <- log(open)
# new time series plot
par(mfrow = c(1, 1))
ggplot(df_sub, aes(x = Date, y = Open_tr, group = 1)) +
geom_line() +
xlab("Date") +
ylab("USD (after log transformation)") +
ggtitle("Series after Box-Cox") +
geom_smooth(method = "loess", level = 0)## Don't know how to automatically pick scale for object of type <ts>. Defaulting to continuous.
## `geom_smooth()` using formula = 'y ~ x'![]()
## [1] 14166.75## [1] 0.06487496Obviously the data still has a linear trend, but the variance is much smaller. We haven’t differenced yet, so the upward trend is still apparent. The typical methodology is to difference at \(d = 1\) when dealing with a linear upward trend such as this.
Differencing
We only want to difference once and at lag 1 because we did not observe any seasonality when we first plotted the original time series. The differenced series will represent the change between observations that are \(d\) units of time apart, in this case, \(d = 1\), which is to say one day apart. So our differenced (and transformed) data will represent the change from each value to the next, one day at a time.
par(mfrow = c(1, 1))
open_diff <- diff(df_sub$Open_tr, lag = 1)
autoplot(open_diff) + ggtitle("Series after Differencing at lag 1 after Box-Cox")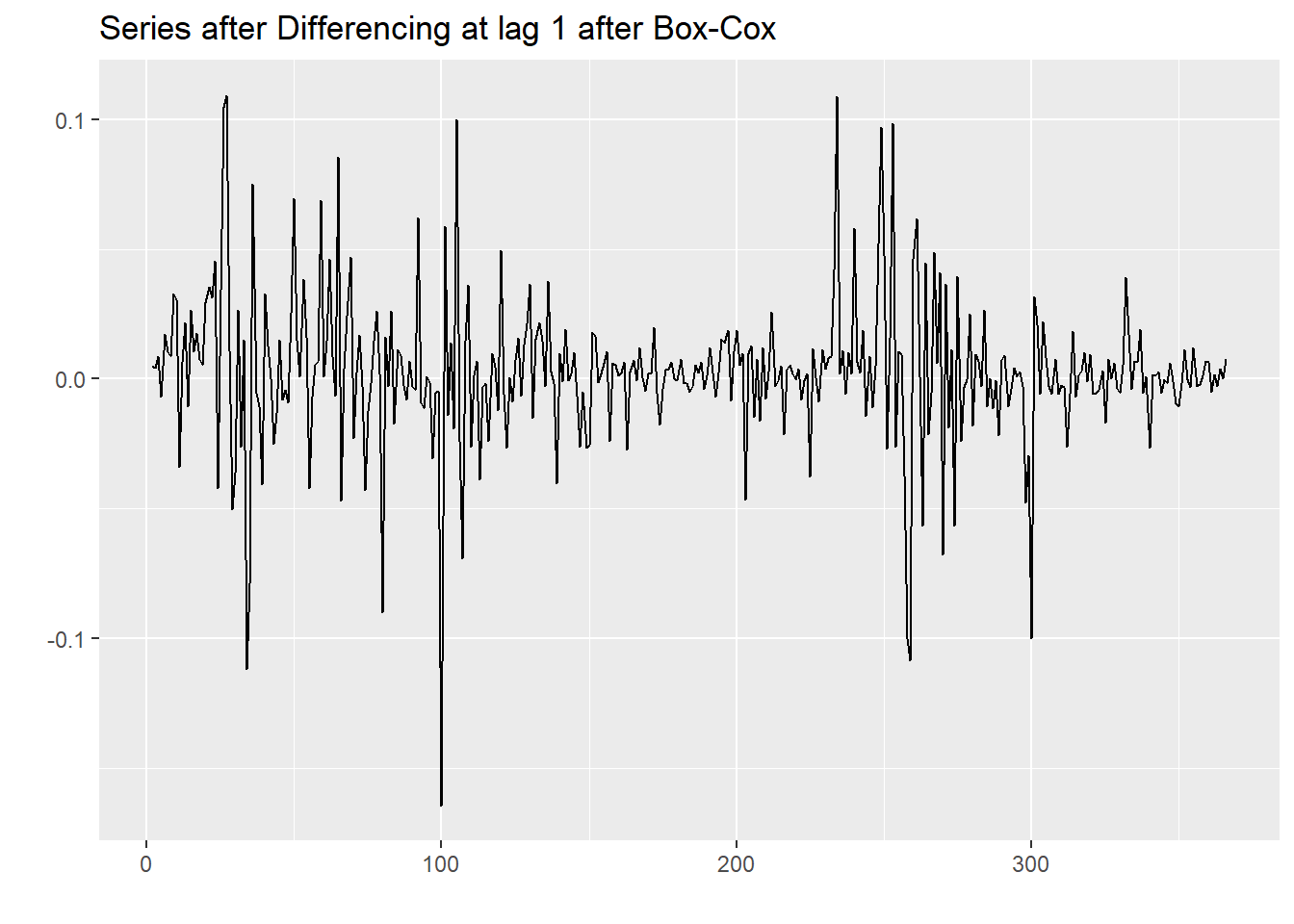
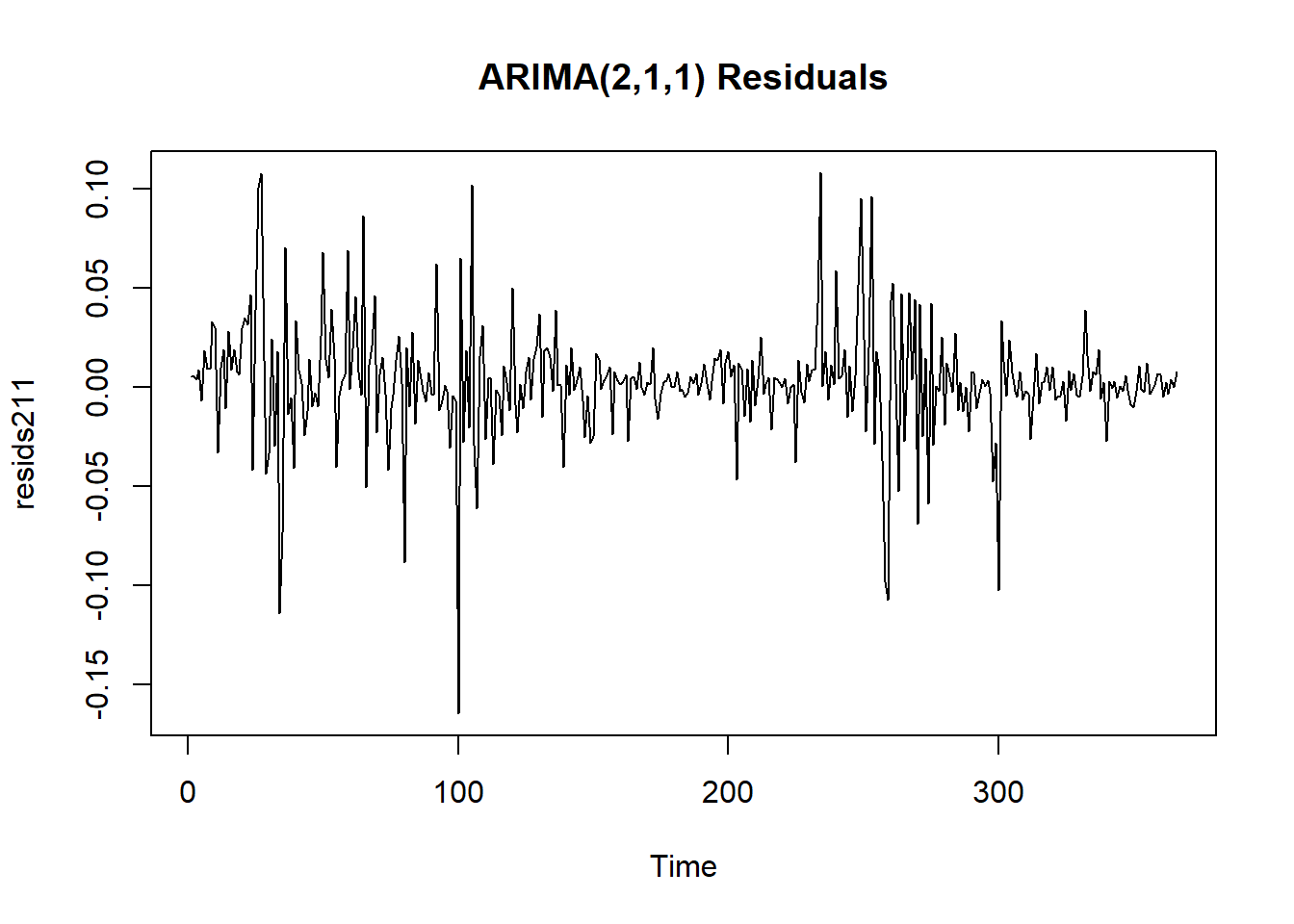
Note that the y-intercept for the trend line is now approximately zero, so our upward trend has been nullified by the differencing. It does concern us that the variance does not appear to be constant throughout (heteroskedasticity) in spite of the Box-Cox transformation being applied, which is theoretically the best power transformation available. In the graph it is noted how the variance is extremely small at certain points, and at other times very large. We can however proceed with an augmented Dickey-Fuller test which will determine whether the data is stationary or not by checking against null hypothesis that the sample has a unit root. If it doesn’t, then it is stationary.
## Warning in adf.test(open_diff, alternative = "stationary"): p-value smaller
## than printed p-value##
## Augmented Dickey-Fuller Test
##
## data: open_diff
## Dickey-Fuller = -7.0202, Lag order = 7, p-value = 0.01
## alternative hypothesis: stationaryOur p-value of \(0.01\) being lower than confidence level \(\alpha = 0.05\) gives us significant evidence to reject the null hypothesis that the data is not stationary, thereby concluding that it is. Satisfied by this, we can now move on with estimating the parameters of the model.
Parameter Estimation
Now we want to try and estimate the order of the model i.e. values of
\(p\) and \(q\). We can start speculating on these
values by plotting the ACF and PACF of the newly differenced series. We
can get ideas on what the orders are by using the
auto.arima() function on the original time series, as well
as the ACF and PACF of our transformed series. We’ll include \(\lambda = 0\) as a part of our function so
that it estimates a model of our Box-Cox transformed data.
# library(forecast) is loaded
# stepwise and approximation = F is slower, but more accurate
auto.fit <- auto.arima(open, stepwise = F, approximation = F, lambda = 0, ic = "aicc")
auto.fit## Series: open
## ARIMA(0,1,4) with drift
## Box Cox transformation: lambda= 0
##
## Coefficients:
## ma1 ma2 ma3 ma4 drift
## 0.0462 -0.0766 -0.0212 0.1660 0.0026
## s.e. 0.0519 0.0513 0.0503 0.0556 0.0017
##
## sigma^2 = 0.000833: log likelihood = 778.57
## AIC=-1545.14 AICc=-1544.91 BIC=-1521.74Note the inclusion of a ‘drift’ constant in the model. The
auto.arima() function only includes the drift if it
improves the model, based on AICc, which is the information criterion we
specified to judge the model on, something that will be explained in
more detail later on. We note that the drift \(\mu = 0.0026\) with standard error \(0.0017\), so the confidence interval for it
actually includes zero hinting at this being a rather insignificant
drift.
We are given an ARIMA(0,1,4) model in this case which means it was differenced at lag 1 just like we did earlier, and also the order is \(q = 4\).
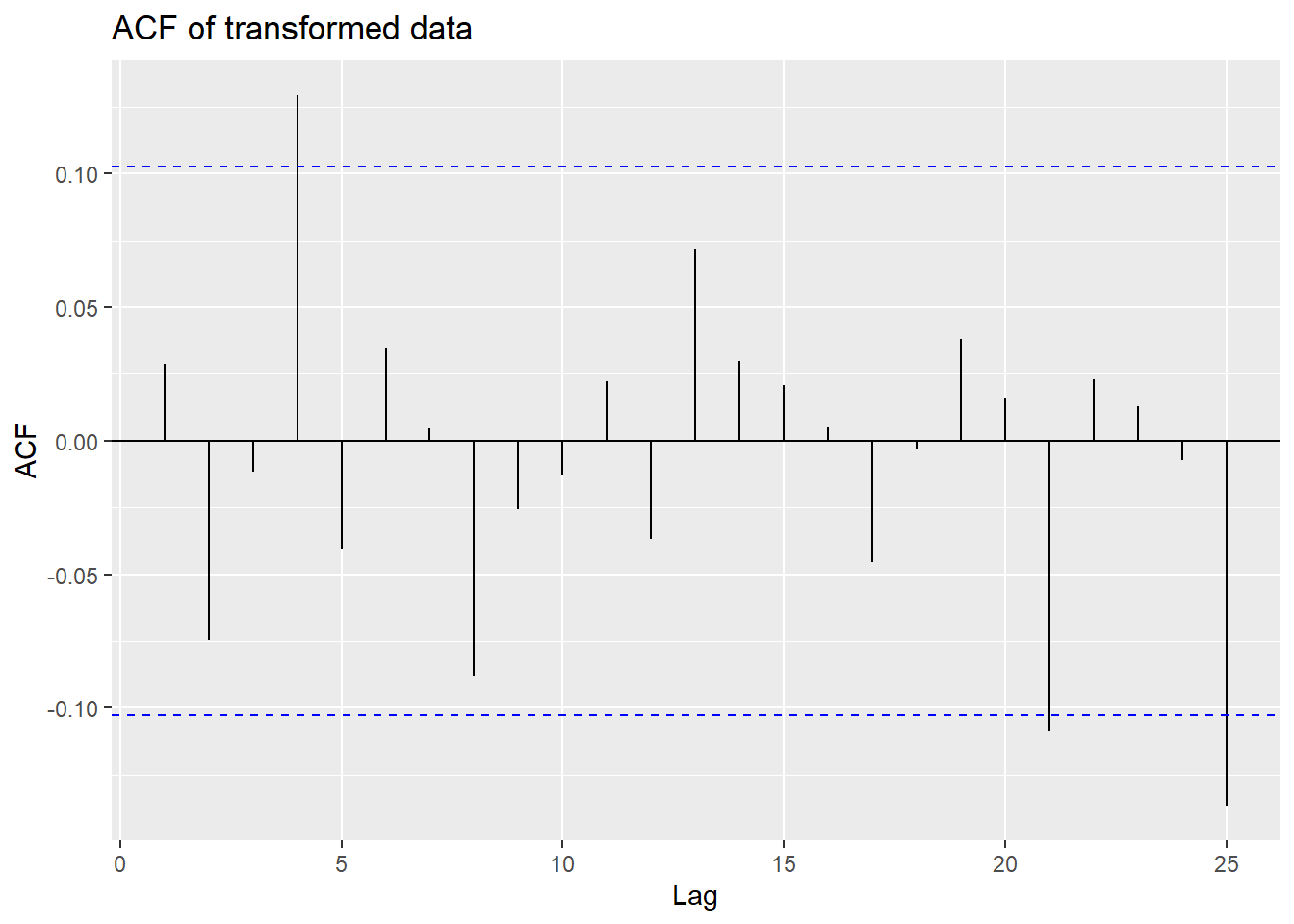
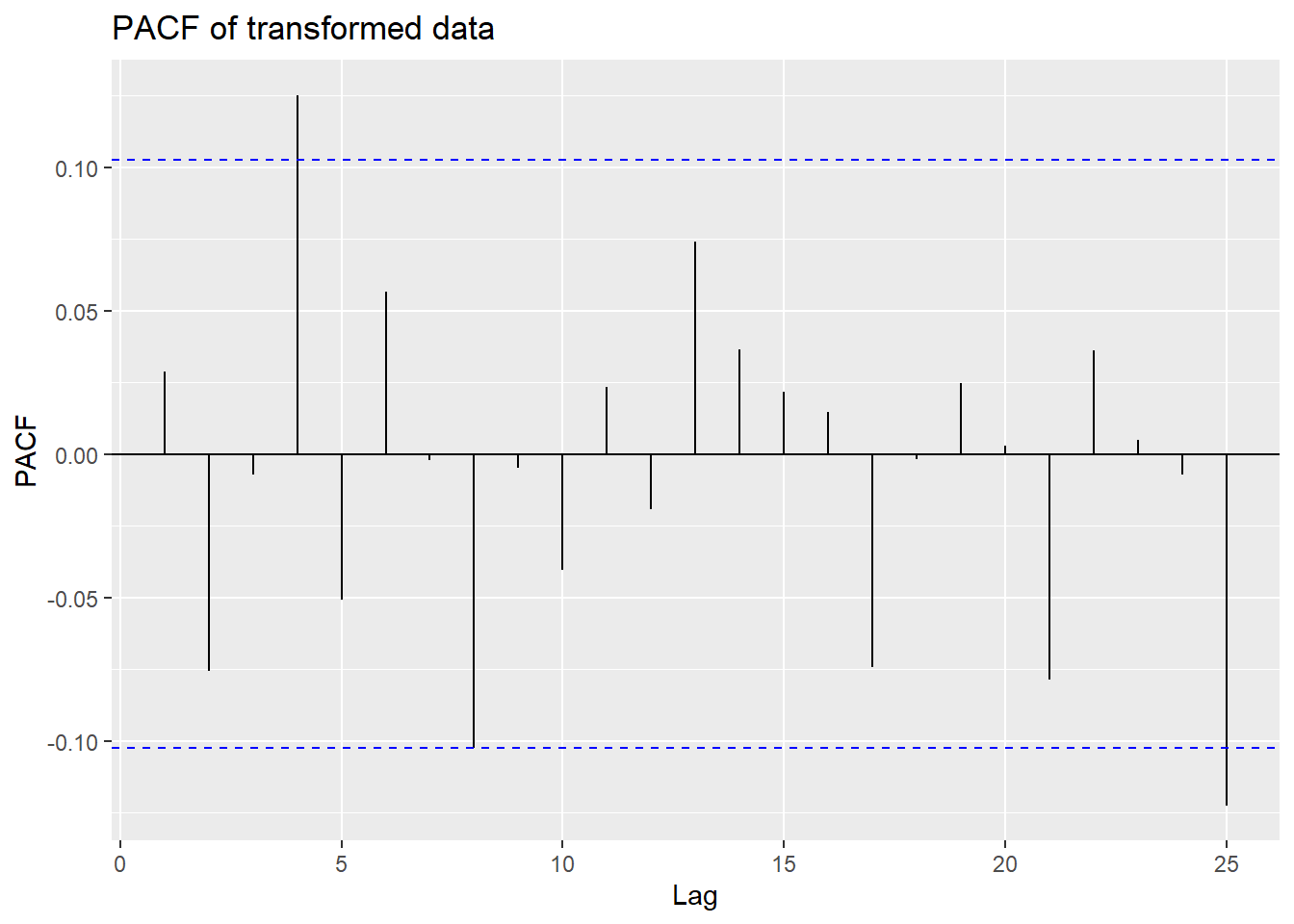
The ACF at lag 1 is not significantly far form zero, so we don’t difference further lest we overdifference the series.
Looking at 25 lags of this series, we see that there are few lags at
which the ACF or PACF are significant. The ACF is significant at lag 4
(implying \(p = 4\)) and the PACF is
significant at lag \(q = 4\) which is
consistent with the model from the auto.arima.
Akaike Information Criterion
AICc is a refinement of the AIC (Akaike Information Criterion), which is a formula based on the number of estimated parameters as well as the maximum likelihood estimator. The smaller the AIC, the stronger the model. The AICc corrects for finite sample sizes, addressing an issue with the AIC which can result in overfitting models, so we prefer it when fitting for an ARIMA model.
It is however important to note that the AIC (and AICc) depend on a model being univariate, linear, and with normally-distributed residuals. We know the first two are true from what we have done so far, but are unsure about the latter condition. It is something that we will diagnose in the model diagnostics.
Model Selection
For now we will just use the AICc to select a couple of models and determine later on if the residuals will be an issue.
# matrix of AIC values for p and q
# library(qpcR) and library(forecast) are loaded
AICc.mat <- matrix(
data = NA, nrow = 5, ncol = 5,
dimnames = list(
paste("p =", 0:4),
paste("q =", 0:4)
)
)
# simulating arima models for p,q = 0,1,2,3,4 and d = 1
for (p in 0:4) {
for (q in 0:4) {
AICc.mat[p + 1, q + 1] <- AICc(Arima(open,
order = c(p, 1, q),
method = "ML", lambda = 0
))
}
}
# printing matrix
AICc.mat## q = 0 q = 1 q = 2 q = 3 q = 4
## p = 0 -1541.736 -1540.275 -1539.475 -1537.564 -1544.742
## p = 1 -1540.202 -1538.621 -1537.460 -1539.345 -1543.171
## p = 2 -1539.853 -1537.820 -1541.075 -1541.256 -1541.248
## p = 3 -1537.821 -1535.777 -1541.447 -1536.959 -1539.292
## p = 4 -1542.163 -1541.295 -1539.960 -1538.658 -1542.195We see that the model with the lowest AICC is the ARIMA(1,1,2) model with an AICc of \(-1538.392\), but all of them are very close to one another. The ARIMA(2,1,1) is pretty similar with an AICc of \(-1538.822\).
We want to estimate as few parameters as possible due to the principle of parsimony (to select as few parameters as possible). In our case, the more parameters there are, the weaker the model. We can fit a couple of different models and compare. It is generally advisable in fact to stick to models in which at least one of \(p\) and \(q\) is no larger than 1, since this is likely to lead to overfitting.
## Series: open
## ARIMA(1,1,2)
## Box Cox transformation: lambda= 0
##
## Coefficients:
## ar1 ma1 ma2
## 0.0546 -0.0167 -0.0536
## s.e. 0.4038 0.4003 0.0487
##
## sigma^2 = 0.0008555: log likelihood = 772.76
## AIC=-1537.53 AICc=-1537.41 BIC=-1521.93## Series: open
## ARIMA(2,1,1)
## Box Cox transformation: lambda= 0
##
## Coefficients:
## ar1 ar2 ma1
## 0.0287 -0.0671 0.0098
## s.e. 0.3504 0.0538 0.3480
##
## sigma^2 = 0.0008546: log likelihood = 772.94
## AIC=-1537.89 AICc=-1537.78 BIC=-1522.29So, we have the ARIMA(1,1,2) model \[X_t - 0.0546X_{t-1} = Z_t + 0.0167Z_{t-1} + 0.0536Z_{t-2}\] and the ARIMA(2,1,1) model \[X_t - 0.0287X_{t-1} + 0.0671X_{t-2} = Z_t - 0.0098Z_{t-1}\]
where \(Z_t\) should be approximately white noise with mean \(0\) and variance \(\sigma^2_Z\). It’s important to note that these parameters have large confidence intervals that also include 0 (which imply that the random drift model may apply in this case).
Model Diagnostics
For us to proceed with forecasting with these ARIMA models, the residuals must be IID (independent, identically distributed) Gaussian white noise–that is, there is no trend, no seasonality and no change in variance, as well as a sample mean of approximately zero, and a variance of approximately 1.
We can conduct the Ljung-Box test, the McLeod-Li test, and the Shapiro-Wilk test for normality on our model’s residuals for model diagnostics.
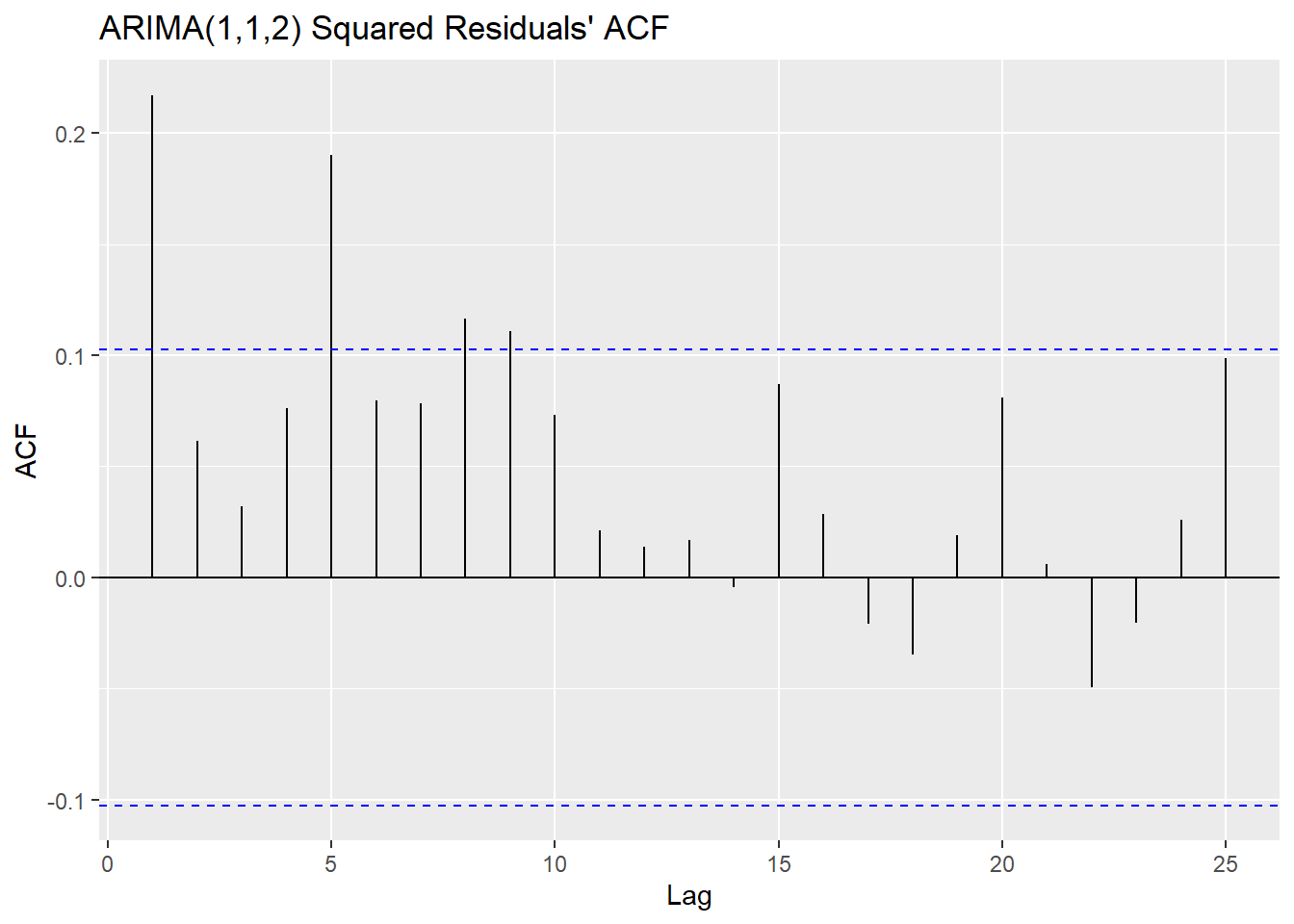
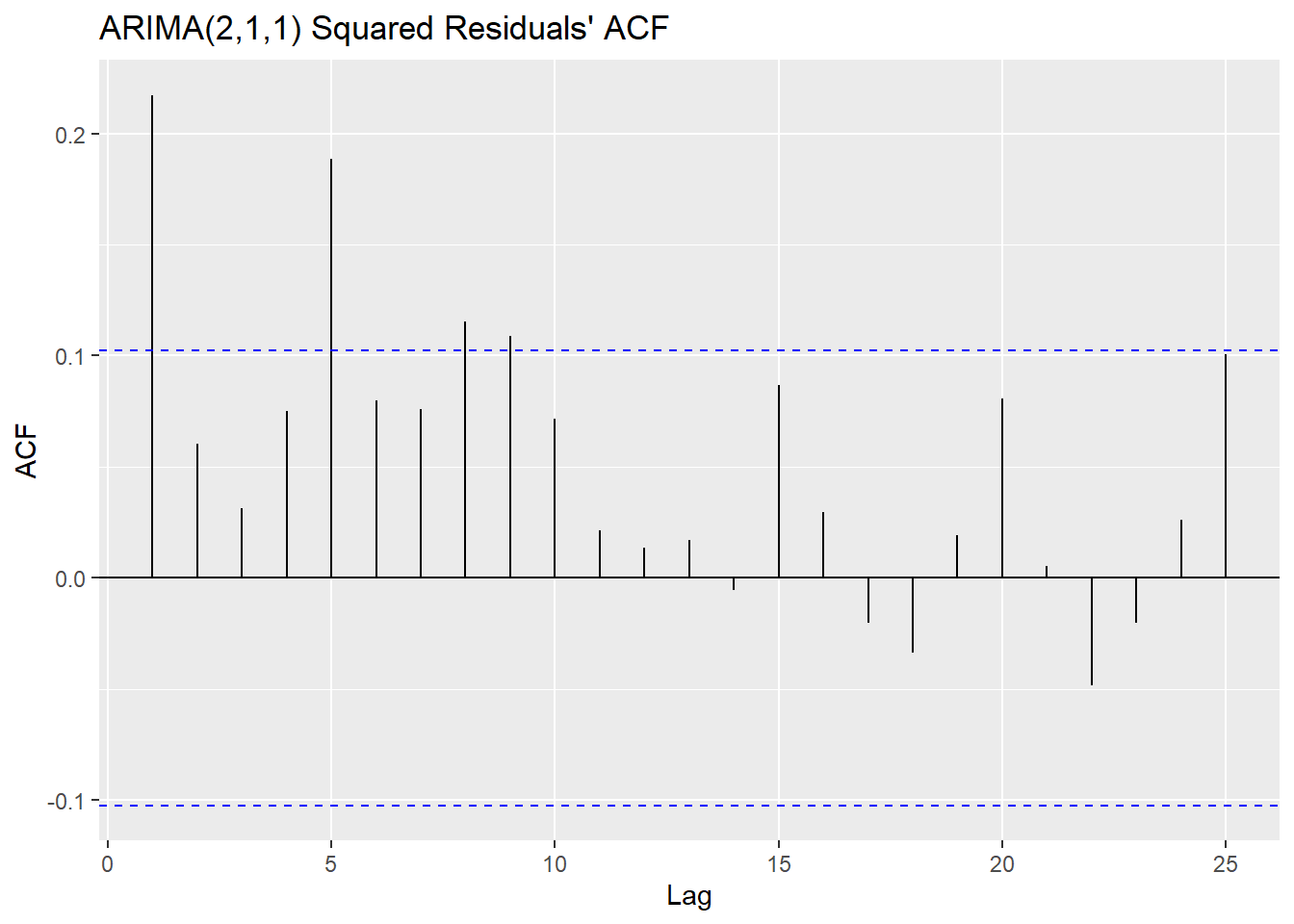
The Ljung-Box test tests some data against the null hypothesis that the data are independently distributed. The McLeod-Li test is the same as conducting the Ljung-Box test, but on the squared residuals instead. The implication of rejecting the null in the McLeod-Li test but passing the Ljung-Box test is an inherent problem of non-constant variance (heteroskedasticity), which is something we noted before in preliminary plots before and after transforming and differencing. The Shapiro-Wilk tests against the null hypothesis that the data are Normal, the other important condition of an ARIMA model’s validity. Here we create a matrix comparing the p-values of each of the hypothesis tests on each model.
resids112 <- fit112$residuals
resids211 <- fit211$residuals
k <- round(sqrt(length(open)))
# a matrix comparing p-values for the three different tests
diag.mat <- matrix(
data = NA, nrow = 2, ncol = 3,
dimnames = list(
c("ARIMA(1,1,2)", "ARIMA(2,1,1)"),
c("Ljung-Box", "McLeod-Li", "Shapiro-Wilk")
)
)
# testing ARIMA(0,1,0) residuals
diag.mat[1, 1] <- Box.test(resids112, type = "Ljung-Box", lag = k, fitdf = 0)$p.value
diag.mat[1, 2] <- Box.test(resids112^2, type = "Ljung-Box", lag = k, fitdf = 0)$p.value
diag.mat[1, 3] <- shapiro.test(resids112)$p.value
# testing ARIMA(2,1,0) residuals
diag.mat[2, 1] <- Box.test(resids211, type = "Ljung-Box", lag = k, fitdf = 2)$p.value
diag.mat[2, 2] <- Box.test(resids211^2, type = "Ljung-Box", lag = k, fitdf = 2)$p.value
diag.mat[2, 3] <- shapiro.test(resids211)$p.value
# matrix of p-values
round(diag.mat, 3)## Ljung-Box McLeod-Li Shapiro-Wilk
## ARIMA(1,1,2) 0.670 0 0
## ARIMA(2,1,1) 0.558 0 0In the case of both models, the residuals fail to reject the null hypothesis in the Ljung-Box test, but have overwhelming evidence to reject it in the case of the McLeod-Li and the Shapiro-Wilk test. All tests use an \(\alpha = 0.05\) confidence level. These conclusions imply that while the residuals are all independently distributed, the squared residuals are not. They also tell us that the residuals are not Normally distributed. The fact that the squared residuals are correlated and the lack of normality are both major pitfalls in our ARIMA models, since our model selection and our forecasting are contingent on these assumptions.
Failing to reject the null hypothesis of the Ljung-Box test but rejecting the null hypothesis of the McLeod-Li test tells us that our data might be more typical of a GARCH (generalized auto-regressive conditional heteroskedasticity) model rather than ARIMA as we have fitted here. With the addendum that our model is not necessarily the best one available, we will run diagnostic checks on the rest of the model and proceed with forecasting anyway, just to see what happens.
Forecasting
Now we will proceed with forecasting the next 10 values in the time series using both the ARIMA(1,1,2) and the ARIMA(2,1,1) models, and compare the results with each other and with the true values.
# library(forecast) is loaded
forecast112 <- forecast(df_sub$Open, model = fit112, lambda = 0)
forecast211 <- forecast(df_sub$Open, model = fit211, lambda = 0)
# plotting true values and the forecasts
par(mfrow = c(3, 1))
df_add <- df %>% subset(Date >= "2015-10-09" & Date <= "2016-10-18")
open_add <- as.ts(df_add$Open)
# True Values
autoplot(open_add, xlim = c(300, 375)) + xlab("Days from 10/09/15") + ylab("USD") +
ggtitle("True Values for Opening Price of Bitcoin, 2016-08-03 - 2016-10-18")## Warning: Removed 300 rows containing missing values (`geom_line()`).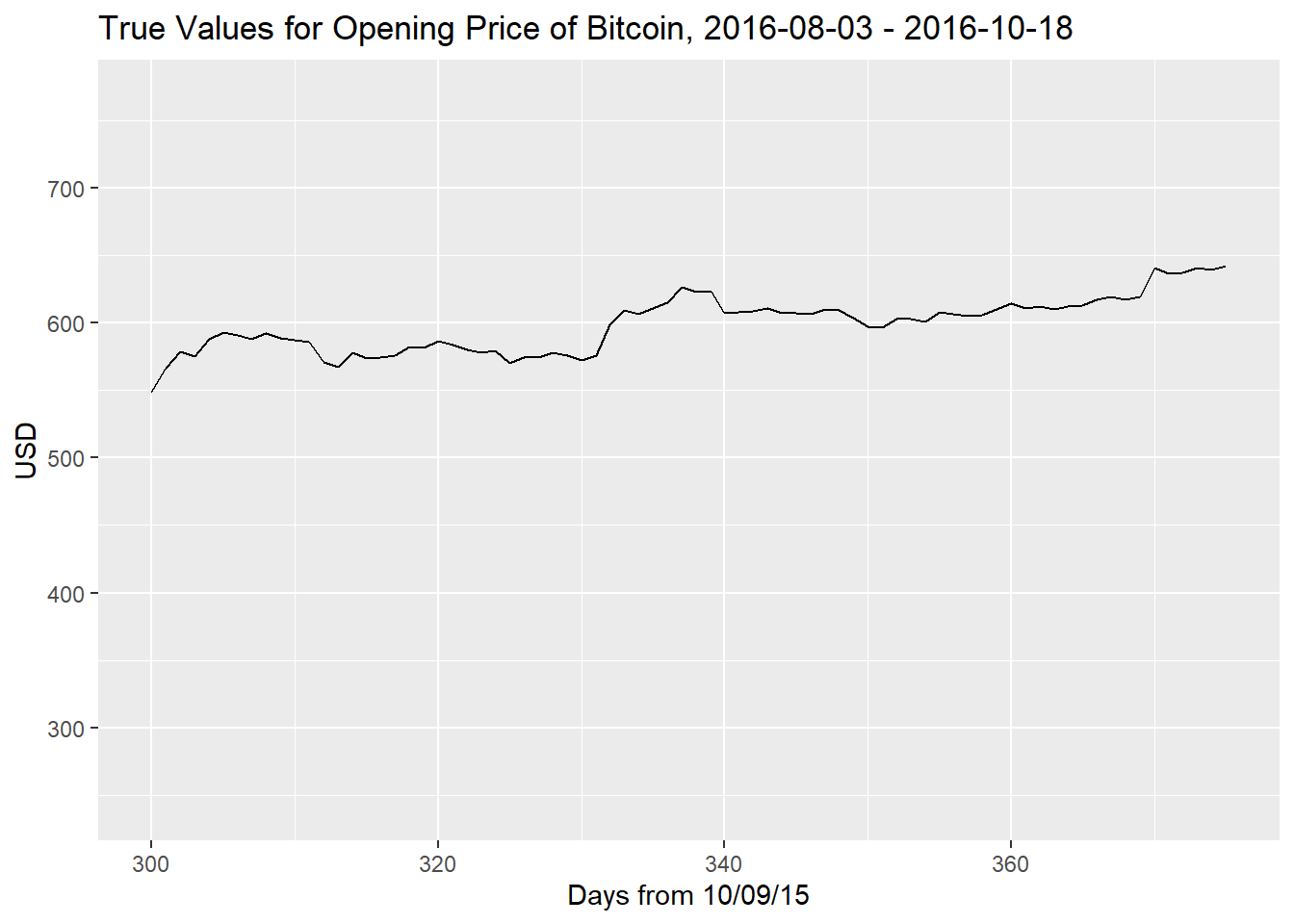
# ARIMA(1,1,2)
autoplot(forecast112, xlim = c(300, 375)) + xlab("Days from 10/09/15") + ylab("USD") +
ggtitle("ARIMA(1,1,2) Forecast for Opening Price of Bitcoin, 10 Days ahead")## Warning: Removed 299 rows containing missing values (`geom_line()`).## Warning: Removed 1 row containing missing values (`geom_line()`).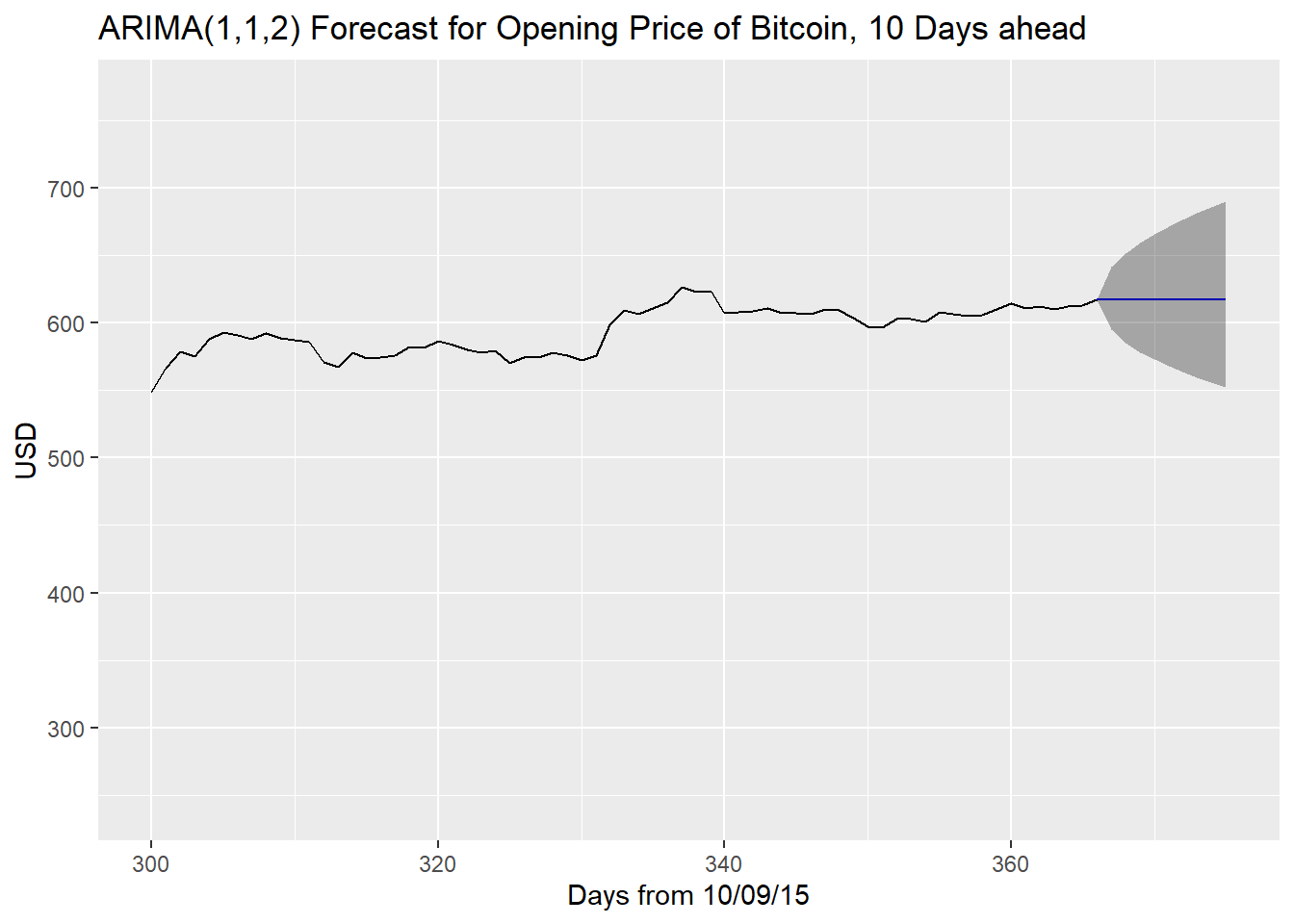
# ARIMA (2,1,1)
autoplot(forecast211, xlim = c(300, 375)) + xlab("Days from 10/09/15") + ylab("USD") +
ggtitle("ARIMA(2,1,1) Forecast for Opening Price of Bitcoin, 10 Days ahead")## Warning: Removed 299 rows containing missing values (`geom_line()`).
## Removed 1 row containing missing values (`geom_line()`).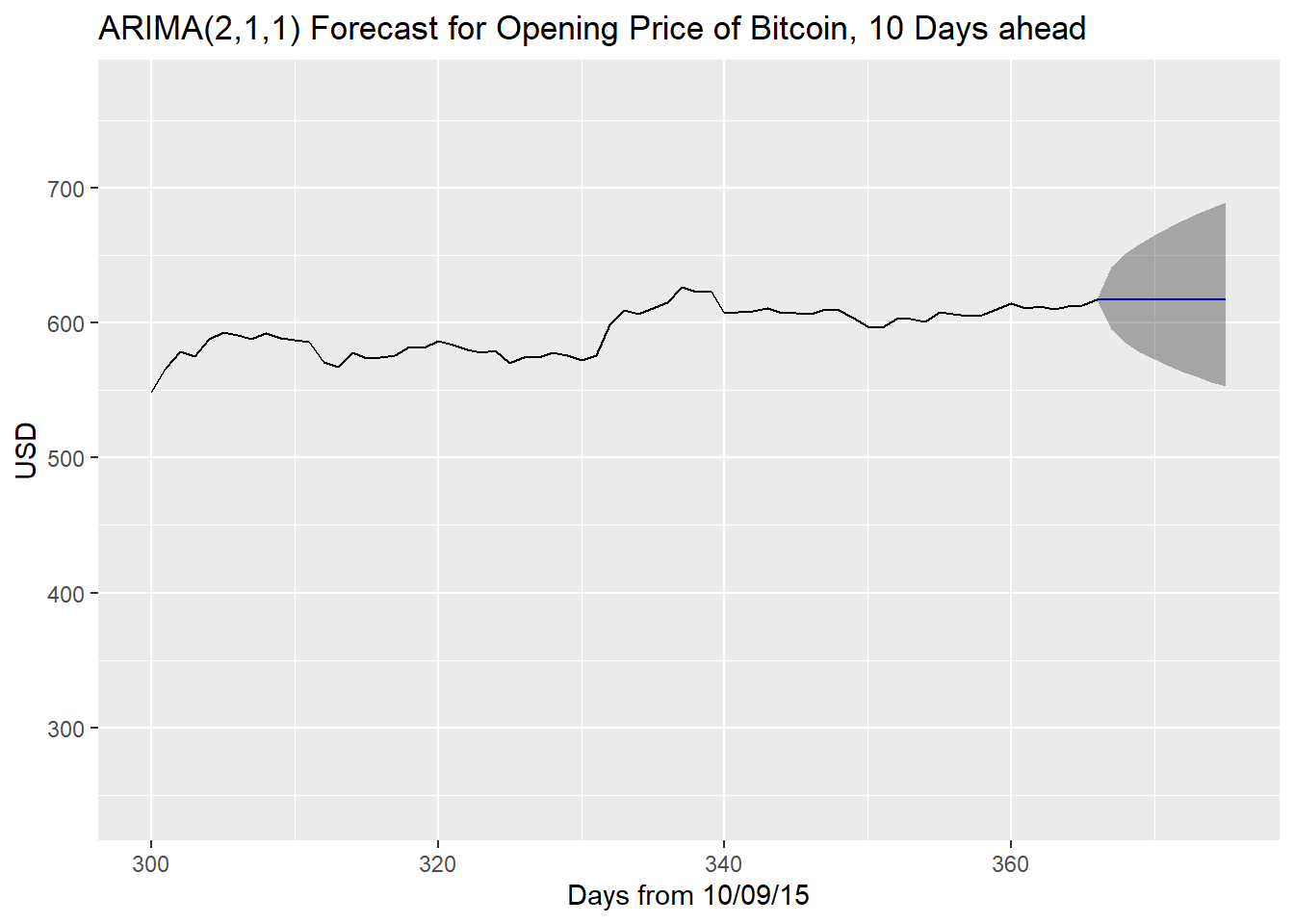
As we can see, the ARIMA(2,1,1) is very similar to the ARIMA(1,1,2) since both models had confidence intervals for their parameters that made them having close to no model at all other than a random walk. We do observe that while the forecasts predict a straight line, which the true values obviously did not follow, at the very least the confidence intervals of the predictions capture the true values. The further one goes into the future, the larger the confidence interval i.e. the more uncertain predictions become.
Here we print out two data frames, one for each model, comparing the
true values, the predictions, the 95% confidence intervals, and the
percent difference between the prediction and the true value (the column
pct.diff). A value of \(4.43\) means that the predicted value is
4.43% bigger than the true value.
true <- df_add$Open[366:375]
# data.frame of ARIMA(1,1,2) forecasts
df112 <- data.frame(
true = true, pred = forecast112$mean,
lower = forecast112$lower[, 2],
upper = forecast112$upper[, 2],
pct.diff = round((forecast112$mean - true) / true, 4) * 100
)
df112## true pred lower upper pct.diff
## 1 617.34 617.5206 583.1163 653.9548 0.03
## 2 619.17 617.2694 568.3204 670.4343 -0.31
## 3 616.82 617.2557 558.4516 682.2518 0.07
## 4 619.24 617.2550 550.2555 692.4123 -0.32
## 5 640.87 617.2549 543.1030 701.5311 -3.68
## 6 636.03 617.2549 536.6973 709.9041 -2.95
## 7 637.01 617.2549 530.8610 717.7088 -3.10
## 8 640.31 617.2549 525.4775 725.0618 -3.60
## 9 639.08 617.2549 520.4648 732.0449 -3.42
## 10 641.82 617.2549 515.7634 738.7179 -3.83# data.frame of ARIMA(2,1,1) forecasts
df211 <- data.frame(
true = true, pred = forecast211$mean,
lower = forecast211$lower[, 2],
upper = forecast211$upper[, 2],
pct.diff = round((forecast211$mean - true) / true, 4) * 100
)
df211## true pred lower upper pct.diff
## 1 617.34 617.5149 583.1276 653.9301 0.03
## 2 619.17 617.2013 568.2658 670.3509 -0.32
## 3 616.82 617.1806 558.6474 681.8467 0.06
## 4 619.24 617.2010 550.6802 691.7574 -0.33
## 5 640.87 617.2030 543.6340 700.7279 -3.69
## 6 636.03 617.2017 537.3100 708.9724 -2.96
## 7 637.01 617.2015 531.5488 716.6561 -3.11
## 8 640.31 617.2016 526.2325 723.8963 -3.61
## 9 639.08 617.2016 521.2804 730.7734 -3.42
## 10 641.82 617.2016 516.6340 737.3456 -3.84## [1] -2.111## [1] -2.119On average, the predictions of the ARIMA(1,1,2) model were closer to the true values of the data, although it was very close, with both being close to 2% off of the true values. Having said that, we do know that the squared residuals of both of these models are not independent from each other (they have an auto-correlation) so we can’t technically declare either of these models truly valid. Also, we have only predicted 10 values into the future here so a larger sample size of predictions is necessary to determine which in the long-run is stronger.
Conclusion
Ultimately, our two lowest AICc models produced predictions that were relatively close to the true data, with the ARIMA(1,1,2) model \(X_t - 0.0546X_{t-1} = Z_t + 0.0167Z_{t-1} + 0.0536Z_{t-2}\) proving only slightly closer than the ARIMA(2,1,1) \(X_t - 0.0287X_{t-1} + 0.0671X_{t-2} = Z_t - 0.0098Z_{t-1}\), but this was only for forecasting 10 values. Again it is important to note that both models did not pass model diagnostics and as such do not carry a lot of validity.
This dataset was difficult to fit with an ARIMA model because of the fact that the variance was non-constant, which results in squared residuals that were dependent on one another. The residuals were also not Normal, even after transforming with the Box-Cox transformation in the beginning. Both issues easily apparent in our time series plot of the original data which has many sporadic bursts up and down. While the residuals themselves were not autocorrelated, this still does not make for a forecast-ready model, at least not with ARIMA.
If someone were to accurately forecast on this dataset, it would be prudent to utilize a GARCH model instead, which better takes into account the non-constant variance. GARCH is a typical model for financial data. Considering our dataset in question is concerning the value of cryptocurrency (which has been extremely variable in the past several years), prospective analysts would be best advised to utilize this model in the future.
References
R Core Team (2017). R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. URL https://www.R-project.org/.
Adrian Trapletti and Kurt Hornik (2017). tseries: Time Series Analysis and Computational Finance. R package version 0.10-42.
Hyndman RJ (2017). forecast: Forecasting functions for time series and linear models. R package version 8.2, <URL: http://pkg.robjhyndman.com/forecast>.
Hyndman RJ and Khandakar Y (2008). “Automatic time series forecasting: the forecast package for R.” Journal of Statistical Software, 26(3), pp. 1-22. <URL: http://www.jstatsoft.org/article/view/v027i03>.
Venables, W. N. & Ripley, B. D. (2002) Modern Applied Statistics with S. Fourth Edition. Springer, New York. ISBN 0-387-95457-0
David Stoffer (2016). astsa: Applied Statistical Time Series Analysis. R package version 1.7. https://CRAN.R-project.org/package=astsa
Andrej-Nikolai Spiess (2014). qpcR: Modelling and analysis of real-time PCR data. R package version 1.4-0. https://CRAN.R-project.org/package=qpcR
Nau, Robert. “Statistical Forecasting: Notes on Regression and Time
Series Analysis.”
Statistical Forecasting: Notes on Regression and Time Series Analysis,
Duke
University, Sept. 2017, people.duke.edu/~rnau/411home.htm.
Shumway, Robert H., and David S. Stoffer. Time Series Analysis and Its Applications: with R Examples. 2nd ed., Springer, 2006.
Metcalfe, Andrew V., and Paul S.P. Cowpertwait. Introductory Time Series with R. Springer New York, 2009.
Appendix
# pretty much all code is included in the body of the report
fit211$coef[1:2] # the 2 AR coefficients## ar1 ar2
## 0.02867388 -0.06710986par(mfrow = c(1, 1))
# RESIDUALS
# residual plots have clear heteroskedasticity
plot.ts(resids112, main = "ARIMA(1,1,2) Residuals")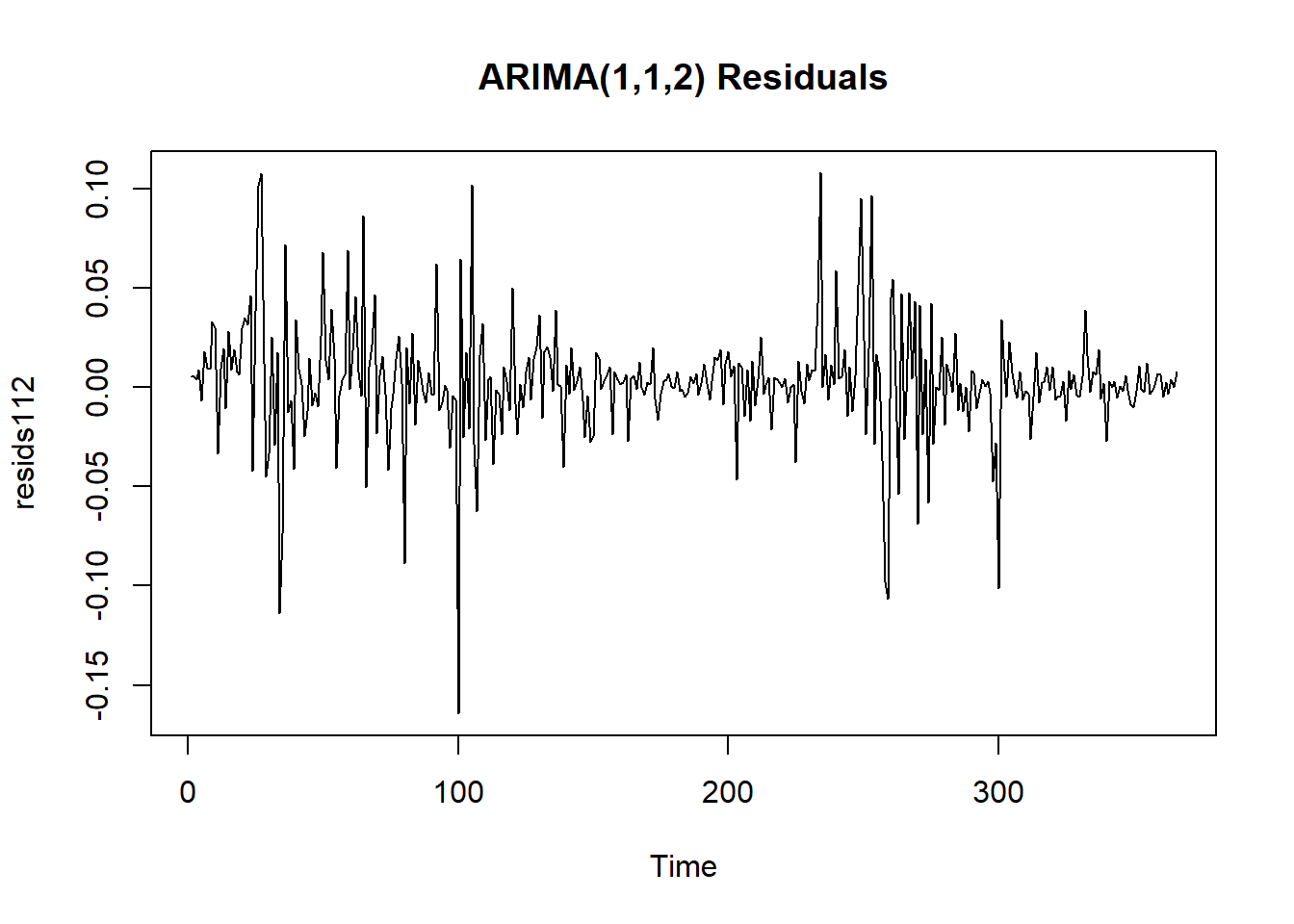
# QQ-plots of residuals
par(mfrow = c(2, 1))
qqnorm(resids112, main = "Standardized Residuals of ARIMA(1,1,2)")
qqline(resids112)
qqnorm(resids211, main = "Standardized Residuals of ARIMA(2,1,1)")
qqline(resids211)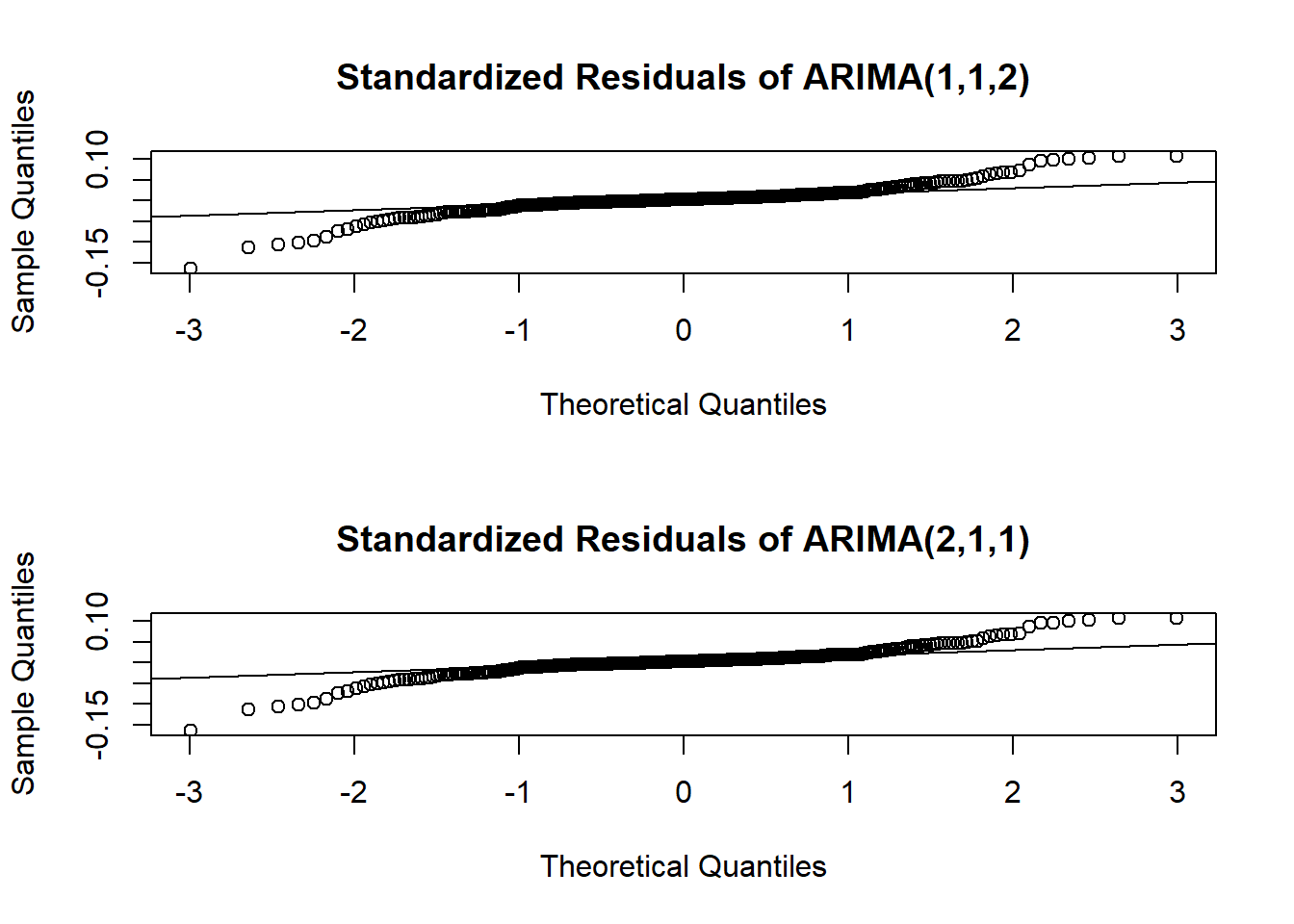
# ACF of residuals
# shows they are uncorrelated at every lag i.e. white noise
ggAcf(resids112) + ggtitle("ARIMA(1,1,2) Residuals' ACF")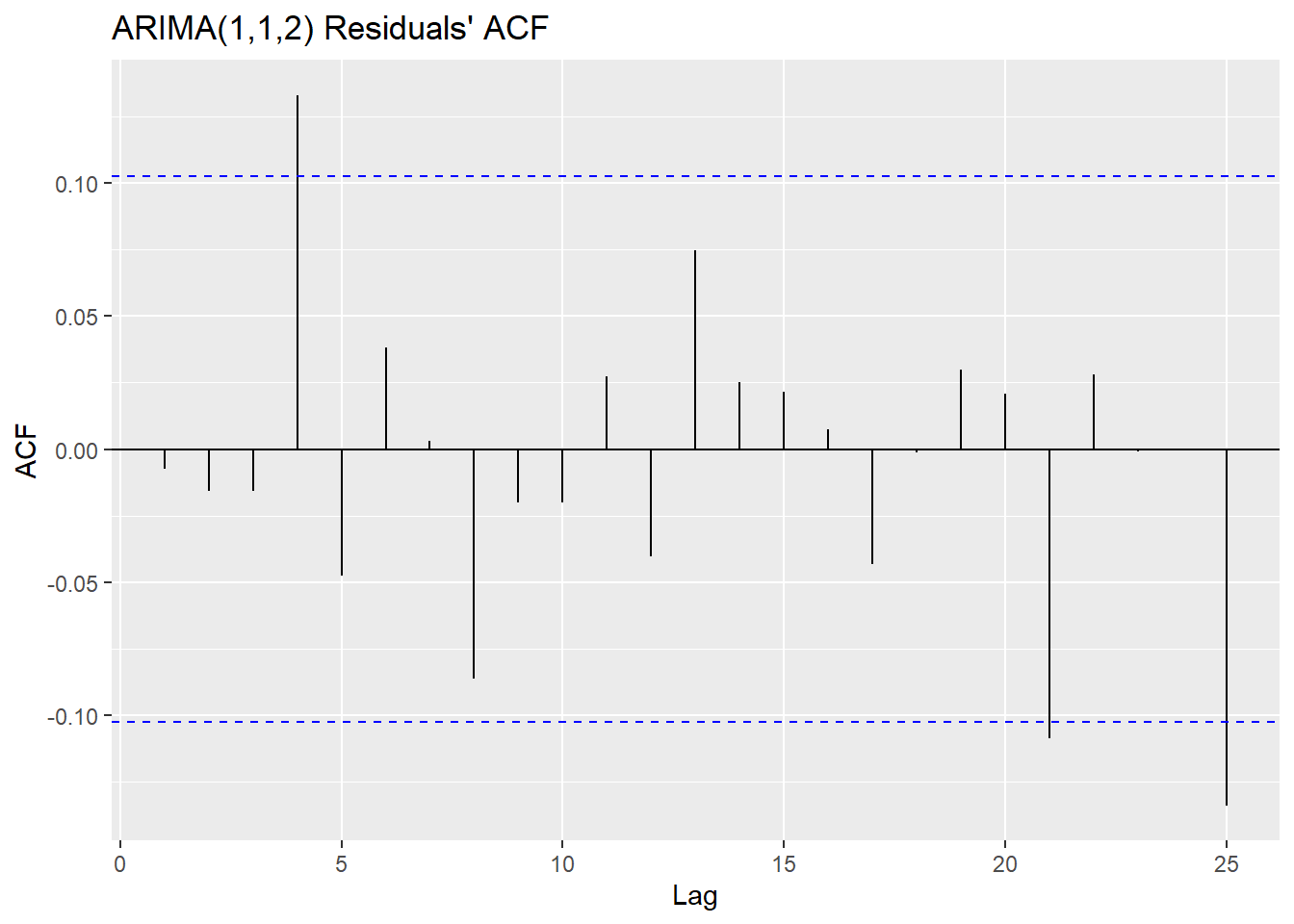
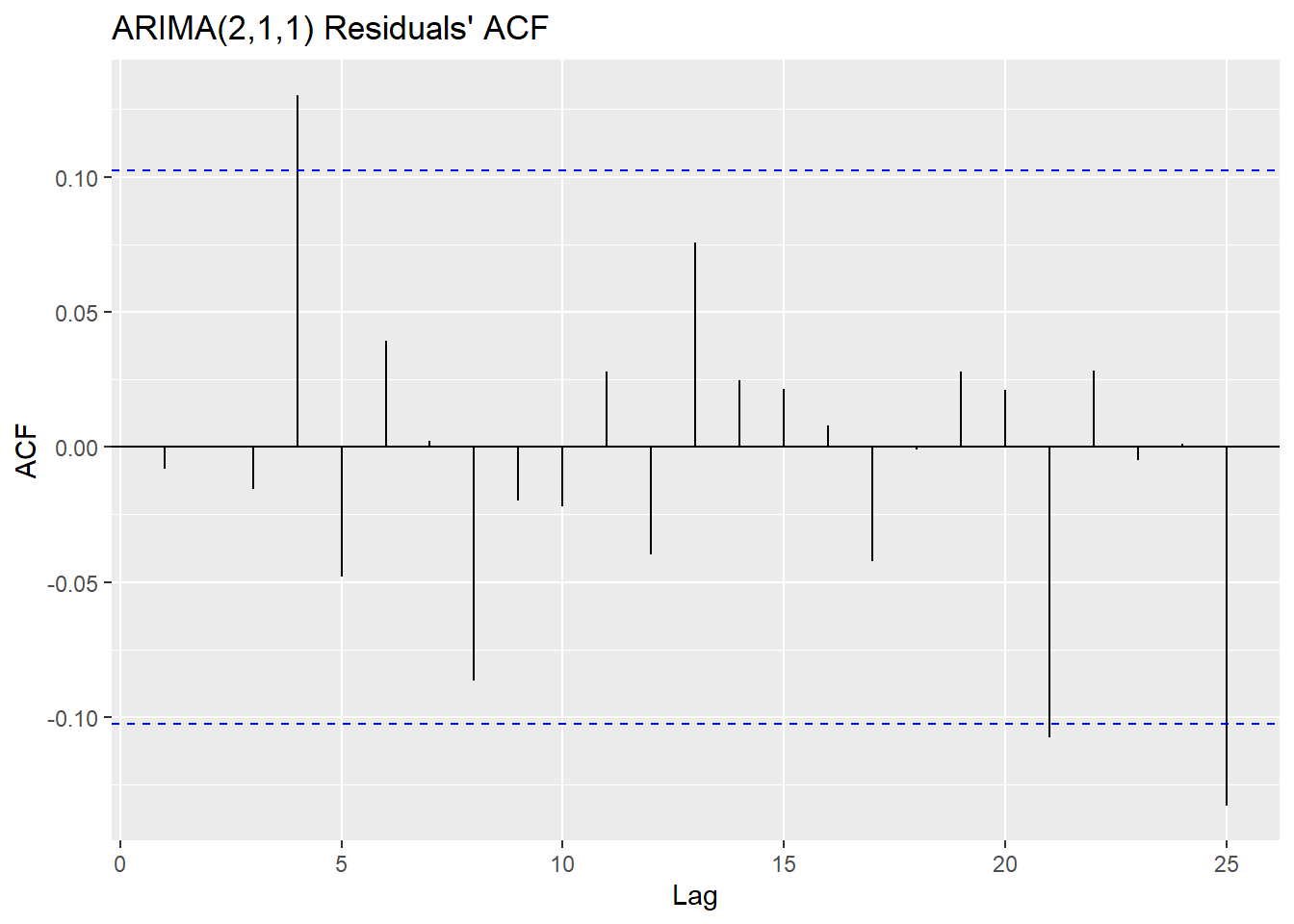
# ACF of squared residuals
par(mfrow = c(2, 1))
# not uncorrelated, i.e. not white noise
ggAcf(resids112^2) + ggtitle("ARIMA(1,1,2) Squared Residuals' ACF")